Did your agent really improve?
We rebuild Terminal Bench 2 as a held-out variant benchmark (TB2-Fn) to test whether terminal agents generalize. Frontier agents fail to hold their scores under task-variant shift, and we show how treating the harness as a substrate can close the gap.

The progress in machine learning has often been driven by defining benchmarks and hill climbing on them to fuel innovation. ImageNet was a foundational effort that helped propel computer vision for a decade. The current approach to AI agent development is no exception. Benchmarks for agents, while imperfect, have generally signaled some degree of generalization in agentic tasks. However, in today’s agent development, it has become trivial for agents to hack the metric without meaningful progress, largely because we still lack a fundamental understanding of how these systems generalize.
This challenge is not new in machine learning. As Recht et al. demonstrated in Do ImageNet Classifiers Generalize to ImageNet? (ICML, 2019), rebuilding a benchmark test set can lead to significant accuracy drops (11–14% top-1 accuracy on ImageNet). This forced the research field to confront a critical question: were models overfitting to specific test cases, or failing to generalize to new task variants? A similar observation resurfaces in code generation tasks: EvalPlus expanded HumanEval’s test coverage roughly 80× and observed pass@k fall by as much as 28.9% across 26 models. Their analysis showed that “passing” solutions had only survived because the original tests were too narrow to catch their bugs.
In this post, we apply that same scrutiny to terminal agents which operate through terminal shells. We evaluate them on Terminal Bench 2 (TB2), a suite of real terminal tasks such as editing files, transforming data, wrangling git, setting up systems, debugging broken environments. In practice, teams working on internal agents like terminal agents do not chase a benchmark leaderboard, but they care how reliably the agents can handle messy, varied tasks in the real world. This makes TB2 a good place to study generalization in agentic systems.
Consider the filter-js-from-html task in TB2, where the goal is to create a Python script that removes JavaScript from HTML to prevent XSS attacks. To trust a terminal agent, we must know if it has truly mastered sanitization or if it has merely memorized a specific solution for a single task.
TB2-Fn
Motivated by Recht et al. (2019), we built TB2-Fn (TB2 Fidian Edition), a new benchmark variant of TB2. In TB2-Fn, we created new task variants that measure similar underlying agent skills as the corresponding TB2 tasks. For instance, look again at the filter-js-from-html task in Terminal Bench 2 (TB2). We can think of at least two variants for this task:

Every variant preserves the original underlying goal which is to strip dangerous content from HTML while keeping the document’s structure intact. We only rewrite the instruction as well as the verification component. To verify the new variant tasks, we ran multiple refinement rounds on every task component, including the environment setup, task instructions, and test script. In each refinement round, we adopted human expert review and Meerkat, an AI audit tool, to review the tasks and example trajectories generated from a sanity agent run. From our data audit log, 51.7% of the task variants were flagged for issues (e.g. potential exploits an agent could use to cheat) and subsequently refined further.
In the last round of refinement, from the data review log, we filtered out any remaining invalid tasks (unsolvable tasks, tasks that are simply duplicates to the original tasks, and tasks where Meerkat flagged with potentially agent exploits). Among the remaining valid tasks, we sample one task variant for each original TB2 task, resulting in a total of 89 new tasks for TB2-Fn.
We then evaluated three frontier LLMs: Gemini 3.1 Pro, Opus 4.7, and GPT 5.5 on both TB2 and our new benchmark TB2-Fn, using two popular terminal agent harnesses (Terminus 2 and Kira) as well as the CLI harnesses native to these models (Gemini CLI for Gemini, Claude Code for Opus, and Codex CLI for GPT). For every model and harness combination, we ran 5 attempts per task and conducted a study to investigate the results. Throughout this post, the error bars on our charts denote the margin of error (MOE), measured as the half-width of the 95% confidence interval around the reported passing rate: , where = reported passing rate and = total number of attempts.
In contrast to an ideal outcome, we observe that all agent × harness combinations fail to maintain the performance from TB2 to TB2-Fn. On non-native CLI harnesses, Gemini falls the most, 15.7 points with Terminus 2 and 11.9 with Kira; GPT drops about 4–6 points and Opus loses the least. On native CLI harnesses, we found that the performance drops across models are between 5–11 points.
What is the real task-variant shift?
Agent benchmarks like TB2 have been known for being imperfect, as well studied in Establishing Best Practices for Building Rigorous Agentic Benchmarks. In another study, AgentLens found that many trajectories in the coding agent benchmarking SWEBench were considered success even though they are just “lucky passes” (incomplete solutions that passed against insufficient test coverage).
Hence, to understand the real performance impacts, we decided to review every original TB2 task and categorized the tasks into the following three groups:
- Score-inflating tasks. These tasks allowed incorrect agents to pass in TB2 via possible exploits, leaked solution secrets, or any task loopholes. These effectively inflated the original benchmark scores.
- Score-deflating tasks. These tasks penalized correct agents in TB2 due to broken environment setup, over-strict test cases, or hidden task requirements. These effectively deflated the original scores.
- Neutral tasks: These were considered correctly constructed tasks. Any performance shift in this group isolates the impact of task variation, stripped of any inflation or deflation effects.
We define the categories of issues for score-inflating tasks and score-deflating tasks below:
| Category | Description |
|---|---|
| Score-inflating tasks | |
| Solution leak | The intended solution (or a hint) is reachable in the task environment. |
| Test loophole | The verifier accepts outputs that do not actually satisfy the task. |
| Score-deflating tasks | |
| Instruction issue | The prompt is ambiguous, under-specified, or hides a requirement only the verifier enforces. |
| Test/verifier issue | The verifier is over-strict or incorrect, rejecting valid solutions. |
| Environment issue | Broken or non-reproducible setup (missing dependencies, build failures, unavailable or insufficient resources). |
To classify TB2 tasks into these categories, we sampled trajectories and employed both human reviewers as well as AI audit tool Meerkat to review not just the tasks (verifier, instruction, environment) but also the sampled traces and generated solutions. We also compared our findings against any community-reported issues on TB2. As a result, we identified 7 score-inflating tasks and 27 score-deflating tasks in total (see Appendix A for the lists of tasks in these groups). These 34 flagged tasks, about 38% of the benchmark, represent prevalent verification bugs.
Using this data split of 7/27/55 samples, we measured the performance across all agents and models (Terminus, Kira, and native CLI harnesses across 3 frontier models) in each split:
First, we can observe that score-inflating tasks collapse by -40 points on average from TB2 to TB2-Fn across all model × harness runs. This means that TB2 had overestimated these agents in solving these tasks (with 77.5% passing rate), but the reality is an agent success rate of only 37.5%.
Secondly, score-deflating tasks recovered from 47.3% in TB2 to 56.2% in TB2-Fn. While modest (+8.9 points), this recovery is significant because it occurred despite the task being rewritten into a new variant, which otherwise would pull the scores down.
Finally, in the neutral group, we observed a task-variant shift of -12 points, a deeper decline than the -7.9 points when measured on all 89 tasks. This deeper decline here reflects the true “robustness gap”, the extent to which agents fail when faced with task variation.
Which agent is sensitive to the real task-variant shift?
To understand why our initial findings on the full 89-task benchmark may be misleading, we analyzed how each model’s performance delta from TB2 to TB2-Fn distributes across the above three data categories.
Crucially, following Miller (2024), we also designed a paired test with bootstrap: every TB2-Fn task has a parent TB2 task, and each task is measured with multiple attempts. So far the MOE error bars we have reported describe each passing rate on its own, but the quantity we actually care about is the delta, which carries two nested sources of noise: (1) which tasks happen to be in the set, and (2) run-to-run nondeterminism within each task.
We therefore tested the per-task performance change with a task-level clustered bootstrap by resampling both tasks and attempts-within-task (see Appendix B for the implementation details of our test). We report the 95% confidence interval of the delta per model next to the average number:
| Model | Score-inflating Δ [95% CI] | Score-deflating Δ [95% CI] | Neutral Δ [95% CI] |
|---|---|---|---|
| Gemini 3.1 Pro | −36.2 [−63.8, −10.5] | +1.0 [−19.2, +20.4] | −14.4 [−24.4, −5.5] |
| Opus 4.7 | −35.2 [−64.8, −9.5] | +13.3 [−8.2, +34.1] | −10.5 [−20.1, −0.9] |
| GPT 5.5 | −48.6 [−77.1, −21.0] | +12.0 [−5.8, +33.2] | −11.2 [−20.7, −2.1] |
Under this test, we found that the shifts are statistically significant for the score-inflating and neutral groups (intervals exclude zero) but not for the score-deflating group. Still, the deflating point estimates are large and positive for GPT (+12.0) and Opus (+13.3), suggesting TB2’s broken verifiers were likely holding them down, but not penalizing Gemini.
Secondly, in the neutral tasks, the statistically significant performance drops indicate current models are still sensitive to task-variant shifts, even when stripping noisy tasks. We found this per-model divergence under task-variant shift in TB2-Fn is related to the underspecification phenomenon of D’Amour et al. (2022): models with near-identical benchmark scores can behave very differently under data distribution shifts. Let us strip out the noisy splits and look only at the results on the 55 neutral tasks:
Comparing all models, we still could not find a consistent pattern like what Recht et al. (2019) found: their model performance drops in ImageNet task variants are very consistent, following linear approximation from the original ImageNet results. In our case, while we only have limited data points (3 models × 3 harnesses = 9 data points), we can explain this discrepancy by existing foundational language models being trained with far more massive amounts of data than traditional ImageNet models; hence, it could be possible that some models might be exposed to test tasks (as noted by Dominguez et al. (2025)) and more sensitive to the task-variant shift in TB2.
Difficulty-controlled task variants
Before we can conclude that models such as Gemini can be significantly more sensitive to task-variant shift, we reviewed again how well our TB2-Fn task variants were constructed. This is motivated by Engstrom et al. (2020) and more recently Sturgeon (2026) who found that replicated benchmarks such as ImageNet-v2 and GSM-Symbolic (a variant of GSM8K benchmark) can inflate the performance drops from the original benchmarks if the task construction mechanisms were not properly designed and audited.
Therefore, in this section, we recreated task variants such that their levels of difficulty are more controlled. Specifically, we developed four specific criteria to accept any new task variant:
- C1 - solvability: a reference solution exists and passes all tests
- C2 - skill equivalence: the variant exercises the same skillset/capabilities as its parent TB2 task.
- C3 - cost equivalence: the reference solution’s cost stays within 1.5× of the parent’s, in both trajectory length (tokens) and execution time.
- C4 - construction discipline: the variant is produced only by rule-based, difficulty-preserving surface transforms. Inspired by Sarkar et al. (2023), we defined 3 categories of surface transforms, namely input shift, output shift, and environment shift (see Appendix C for the description and example of the transforms).
We denote a task variant that passes all criteria 1 to 3 as a difficulty-controlled task while one that passes all 4 criteria as difficulty-invariant. For criteria 2 and 3 above, note that a difficulty-invariant task’s reference solution is the original task’s oracle solution that was transformed at the surface (e.g. by renaming output artifacts) following the task transformation rules; for a difficulty-controlled task, its reference solution was authored by Opus 4.8, reviewed by humans, and must pass all tests in the corresponding tasks.
For experiments in this section, we sampled 11 TB2 tasks out of the above 55 neutral tasks (see Appendix D for the list of 11 tasks). For each original TB2 task, instead of measuring the results on a single task variant, we created 10 different difficulty-controlled tasks (denoted TB2-Fn-C) and 10 difficulty-invariant tasks (denoted TB2-Fn-I). Please see Appendix D for more details of our task construction pipeline.
We can compare all three variants against each criterion in the following table:
| Criterion | TB2-Fn | TB2-Fn-C | TB2-Fn-I |
|---|---|---|---|
| C1 - solvability | ✓ | ✓ | ✓ |
| C2 - skill equivalence | ✓ | ✓ | |
| C3 - cost equivalence | ✓ | ✓ | |
| C4 - construction discipline | ✓ |
Similar to previous experiments, we ran 5 attempts per task variants and reported the passing rate per model in each variant set, first broken down by harness:
and then pooled across all harnesses:
We also performed pair tests like before by following Miller (2024) and reported the averages of performance deltas and their 95% confidence intervals per model:
| Model | TB2 → TB2-Fn-I Mean Δ [95% CI] | TB2 → TB2-Fn-C Mean Δ [95% CI] | TB2 → TB2-Fn Mean Δ [95% CI] |
|---|---|---|---|
| Gemini 3.1 | −8.9 [−21.0, +2.6] | −21.7 [−42.5, −0.6] | −54.6 [−71.2, −38.2] |
| Opus 4.7 | −5.6 [−11.4, +0.7] | −14.8 [−26.7, −3.5] | −39.1 [−58.3, −19.1] |
| GPT 5.5 | −1.6 [−7.9, +4.4] | −16.0 [−31.2, −3.5] | −41.2 [−58.8, −24.2] |
Similar to Engstrom et al. (2020), we observed that the original performance drops in TB2-Fn were inflated when we strictly controlled the level of difficulty in task variants in TB2-Fn-I and TB2-Fn-C. Secondly, we found that the more a variant set departs from its parent tasks, the larger the measured performance drop. Thirdly, in the difficulty-invariant set TB2-Fn-I, we observe that the 95% confidence intervals of deltas span over zero, and hence, performance drops are not statistically significant for these variants. However, across all three dataset variants, even on the difficulty-controlled set TB2-Fn-C, compared to Opus and GPT, Gemini’s average estimate shifts are larger than other models’. These observations suggested that Gemini is more sensitive to even difficulty-controlled shifts than other foundational models.
Are the tasks really difficulty-controlled? To quantify difficulty divergence across the three variant datasets, we used realized solution’s cost ratios relative to the original TB2 tasks. Specifically, we calculated these by analyzing generated trajectory logs, extracting token counts, episodes (agent turns), and agent runtime. Note that we reported these metrics here to reflect the genuine difficulty levels and validate our task designs. Hence, we filtered the data to include only successful traces to exclude any cost overhead from failure attempts.
Because a cost ratio is the agent cost on a task variant divided by the cost on its parent TB2 task, we summarized the statistics below with the geometric means of the ratios and performed a paired test like before by following Miller (2024):
| cost ratio | TB2-Fn vs. TB2, geo. mean [95% CI] | TB2-Fn-C vs. TB2, geo. mean [95% CI] | TB2-Fn-I vs. TB2, geo. mean [95% CI] |
|---|---|---|---|
| Tokens | 1.69× [1.08, 2.68] | 1.02× [0.93, 1.12] | 1.00× [0.91, 1.10] |
| Turns | 1.29× [1.04, 1.61] | 0.99× [0.95, 1.07] | 0.99× [0.94, 1.05] |
| Runtime | 1.38× [1.06, 1.83] | 1.09× [0.99, 1.20] | 1.07× [0.97, 1.18] |
From the statistics, we observe that as we tighten the difficulty level, the realized cost ratios against the original tasks (by trajectory tokens, episodes, and agent runtime) also gradually reduce (TB2-Fn > TB2-Fn-C > TB2-Fn-I). This shows that our criterion of cost equivalence can be used as a good proxy to design difficulty-controlled task variation.
Did the model memorize the original tasks? In our initial analysis, we performed simple text pattern matching in Gemini’s generated trajectories and did not find evidence of the model reciting the same solution or artifacts (e.g. file names, data paths, output names) as the trajectories in the original task. We suggest more sophisticated methods such as Li et al. (2025) could be used to diagnose the output artifacts for any evidence of model memorization. In this post, we only highlight the significant performance drops of Gemini are likely due to both a capacity gap (as shown in the results on our TB2-Fn neutral tasks) and adaptivity limit (as shown in the results on our difficulty-controlled variants TB2-Fn-I/C).
Case study: Improve Gemini by its agent harness
From our results, we have found that Gemini is more vulnerable when evaluated under rigorous tests. So how do we act on this? Improving a foundation model is not easy, requiring massive amounts of data and incurring significant compute cost.
Here it helps to remember that an agent is never just its underlying model. It is the model + the harness that wraps it: the system prompts, tool definitions, context management, and control flow that turn a language model into an agent. Recent research such as Code as Agent Harness and Meta Harness considered harness as an important substrate to improve agent capabilities, boosting the performance of the agents by optimizing the different components of the harness. Hence, harness should be treated as a critical part of the agent (as also positioned here by Lee, 2026), complementing foundational large language models the agent is based on.
In this section, we conducted a simple case study to improve Gemini at the agent harness level. Specifically, we ran a harness improvement loop where task variants are created and the agent must improve across all variants:
- Expand a task: we first expand an input task into a family of task variants. This ensures that when we measure the agent, we are measuring a capability, not a single test instance.
- Run and evaluate: We run the agent across the entire task family for multiple attempts and look for patterns in behavior across the variants.
- Diagnose failure modes: Once evaluation is complete, we move from scoring to trajectory-level diagnosis. We audit agent trajectories to isolate the root cause of failure and look for the “why” behind every regression.
- Engineer patches: Finally, we engineer surgical patches to the harness, such as refining system prompts, adjusting tool constraints, or updating the execution flow.
To see this in action, let’s look at how we applied this loop to patch Kira harness for Gemini on an example task in TB2. Here, we look at the large-scale-text-editing task whose goal is “to transform a large CSV file (1 million rows) using efficient Vim macros. The agent must create a Vim script that defines three distinct macros to transform a csv to match another csv byte-for-byte.”
First, we can think of several ways to expand the tasks into 5 task variants:
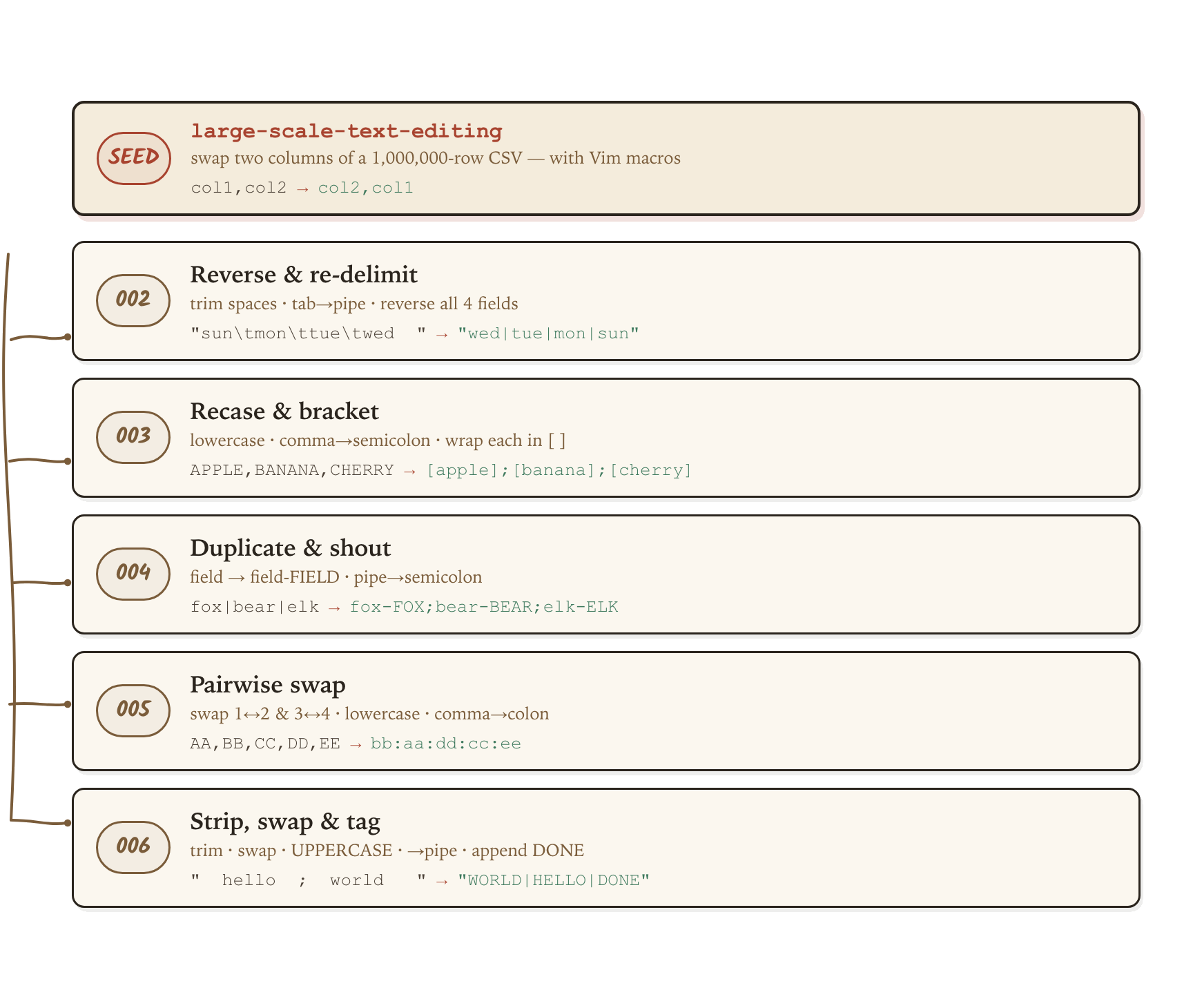
Each task variant keeps the seed task’s core challenge intact, which is to rewrite every one of one million rows with three Vim macros, in under 200 keystrokes, matching the expected output byte-for-byte. We only change the surface of the task: the delimiter, the casing, the column order, the field count, or the whitespace padding.
Even though the transformations look different, every variant stresses the agent capabilities to handle large-scale data efficiently in limited command budgets. So a harness that overfits the original seed task, (e.g. one that has effectively memorized its actions for two-column swap) won’t hold up across this task family.
Now let’s look at how we can improve Gemini agent harness iteratively (hover on a patch or analysis box to see the full content):
We tracked our progress through four distinct iterations:
Iteration 1: The agent struggled with high-volume data manipulation, resulting in a 60% pass rate. Diagnostic analysis revealed the agent frequently relied on heredoc syntax, which caused the shell to hang and triggered timeout errors.
- Patch 1: We implemented a system prompt rule discouraging heredoc usage and modified the harness to inject keystrokes if the shell stalls.
Iteration 2: This improved performance on complex task variants, lifting the overall pass rate to 77%. However, we found a new failure mode: the agent was wasting turns attempting to debug Vim macros across the entire one-million-row dataset, again leading to timeout errors.
- Patch 2: We added a constraint encouraging the agent to verify Vim macros on a small data subset before scaling to the full dataset.
Iteration 3: The aggregate pass rate remained stagnant at 77%, revealing a classic “whack-a-mole” dynamic. While the new patch solved our data-volume issues (jumping success rates on specific difficult tasks from 40% to 100%), it inadvertently regressed other tasks. Our trajectory-level analysis showed that the heredoc hang re-emerged in these regression trajectories.
Crucially, these regression cases were only detected because we evaluated the agent across the entire task family. Had we relied on a standard aggregate score, the 77% metric would have looked flat, leaving us blind to the regression introduced by the last patch.
This reflects a similar failure mode documented by AgentLens, which found that “Lucky Passes” (e.g. successes driven by brute-forced retries or partial fixes slipping through test gaps) can hide systemic brittleness. A standard pass rate treats those lucky passes identically to robust successes; our trajectory-level analysis on task variants ensures we don’t falsely identify genuine progress.
- Patch 3: To solve this, we moved from prompt-based guidance to a hard guardrail: we modified the harness to detect heredoc patterns and automatically inject escape sequences.
Iteration 4: The refined agent reached a new high, achieving a 90% average pass rate. With most tasks now succeeding consistently (80–100%), we accepted the patches to the Kira harness.
Evaluation. To make sure that we are not overfitting the patches to the current task family, we evaluated the patched Kira at each iteration on a held-out set of 5 new task variants. These task variants were independently created from the original task and we never used them in our improvement loop.
We observed that the performance gains of our patched Kira transferred well to task variants that were not seen in the improvement loop. This suggests that our Kira patches were not just “hacks” specific to a single failure. In our improvement loop, we refined the harness systematically and applied these patches uniformly across the entire task family. We didn’t just patch a bug but engineered a more robust harness with more generalizable fixes.
Conclusion
In this post, we have advocated that evaluating AI agents requires moving beyond static, narrow benchmarks. As we have shown in our experiments with terminal agents, “success” on a leaderboard often masks a lack of true generalization and can be heavily influenced by systemic verification bugs or lucky passes. True improvement in agentic systems does not come from optimizing for a static score, but from rigorously testing for robustness across task variations and diagnosing failure modes through trajectory-level analysis. Our findings echo a recently growing call for a more rigorous science of AI evaluation (Reuel et al., 2024, Wallach et al., 2025; Salaudeen et al., 2025; Weidinger et al., 2025).
As we showed in our case study to improve a Gemini harness, by treating the agent harness as a critical substrate of agent capabilities, we can systematically address agent vulnerabilities and build harnesses that are resilient to the messy, varied realities of real-world tasks. As agents continue to evolve and scale, our evaluation frameworks must scale in nuance, shifting focus from “can it pass this test?” to “can it reliably solve this problem?”
Citation
If you find this work useful, please cite:
@misc{fidian2026tb2fn,
title = {Did your agent really improve?},
author = {Fidian},
year = {2026},
month = {June},
url = {https://fidian.ai/blog/did-your-agent-really-improve-updated},
}Appendix A
Score-inflating tasks
| Bug category | Tasks |
|---|---|
| Solution leak | fix-git (PR #53), path-tracing (#61), model-extraction-relu-logits (#60), fix-code-vulnerability, cobol-modernization |
| Test loophole | gpt2-codegolf (#62), git-leak-recovery |
Score-deflating tasks
| Bug category | Tasks |
|---|---|
| Instruction issue | adaptive-rejection-sampler (PR #53), build-pmars (#59), configure-git-webserver (#39), query-optimize (PR #53), sam-cell-seg (#45), torch-tensor-parallelism (PR #53), raman-fitting |
| Test/verifier issue | filter-js-from-html (#46), hf-model-inference (PR #53), install-windows-3.11 (PR #53), polyglot-c-py (PR #53), polyglot-rust-c (#37), break-filter-js-from-html (#26), winning-avg-corewars (#17), extract-elf |
| Environment issue | build-pov-ray (PR #53), caffe-cifar-10 (#44), compile-compcert (PR #53), extract-moves-from-video (PR #53), financial-document-processor (PR #53), make-doom-for-mips (#44), mcmc-sampling-stan (PR #53), mteb-leaderboard (#27), mteb-retrieve (PR #53), overfull-hbox (PR #53), torch-pipeline-parallelism (PR #53), train-fasttext (PR #53) |
Appendix B
Following Miller (2024), we designed a paired test with bootstrap as following:
# Inputs (per model):
# tasks : list of tasks
# tb2[i] : list of 0/1 outcomes, TB2 attempts for task i
# tbfn[i] : list of 0/1 outcomes, TB2-Fn attempts for task i
observed_delta = mean( mean(tbfn[i]) - mean(tb2[i]) for i in tasks )
B = 10000
boot = []
for b in range(B):
sampled = random_choice(tasks, size=len(tasks), replace=True) # (1) resample TASKS
diffs = []
for i in sampled:
# (2) resample ATTEMPTS
p = mean(random_choice(tb2[i], len(tb2[i]), replace=True))
q = mean(random_choice(tbfn[i], len(tbfn[i]), replace=True))
diffs.append(q - p)
boot.append(mean(diffs))
CI_95 = (percentile(boot, 2.5), percentile(boot, 97.5))Appendix C
We created the following rules to construct a difficulty-controlled task variant from a TB2 task. Borrowing the input/output shift decomposition of Sarkar et al. (2023), we group our rules into three data shift types:
- Input shift: we perturb the instruction the agent reads while leaving the underlying goal and the verifier invariant (paraphrase instruction, rename identifiers, reorder independent rules).
- Output shift: we move the target artifact the agent must produce, so the verifier checks the same content at a new location (rename output artifact).
- Environment shift: we relocate where the task lives without changing its files or goal (relocate working directory).
| Transform rule | What changes | Why difficulty is unchanged | Example changes (original → variant) |
|---|---|---|---|
| Input shift | |||
| Paraphrase instruction | Instruction wording only | same constraints, only reworded | ”Write a regex expression that matches dates in the format YYYY-MM-DD…” → “Construct a regular expression that captures calendar dates written as YYYY-MM-DD…” |
| Rename identifiers | names of provided files/symbols cited in the task prompt | a pure label swap in task instructions | eval.py → sanity_check.py; sequences.fasta → assembly_inputs.fasta |
| Reorder independent rules | order of constraints in the task instruction | Collective constraints are the same | In regex-log, swap the “February ≤ 29 days” rule and the “no leading zeros in octets” rule |
| Output shift | |||
| Rename output artifact | output filename/path | verifier reads the new file/path with the same expected content | save to /app/date_pattern.txt → save to /app/regex.txt |
| Environment shift | |||
| Relocate working directory | the task environment’s workdir path | same files, different location | /app → /workspace/task |
Appendix D
11 tasks we used for difficulty-controlled task variant experiments:
- dna-assembly
- feal-differential-cryptanalysis
- feal-linear-cryptanalysis
- mailman
- nginx-request-logging
- path-tracing-reverse
- qemu-alpine-ssh
- regex-log
- sparql-university
- sqlite-db-truncate
- tune-mjcf
For each of the 11 tasks, we produced the variant tasks through the following pipeline:
- Construction: We pick a transform from the Appendix C families and apply it consistently across every file of the task, including the instruction.md, tests folder, the reference solutions, and the environment files. We use Opus 4.8 to perform this editing. The two variant types (TB2-Fn-I and TB2-Fn-C) differ in how the reference solution is obtained: for difficulty-invariant tasks (TB2-Fn-I), the transform is purely surface (rename files/identifiers/paths, reorder independent rules, relocate the working directory), so its reference solution is simply the original TB2 reference with the same names/paths rewritten and hence, no new reasoning is introduced. For difficulty-controlled tasks (TB2-Fn-C), the change goes beyond the surface, so Opus 4.8 authors a fresh reference solution that is then reviewed by humans.
- Validation (criterion C1): Every candidate is run through an oracle solution: we execute its reference solution in the task’s Docker container and then run the verifier. The variant is kept only if it scores reward as 1.
- Cost check (C3): We compare the reference solution’s size / trajectory tokens / execution time against the reference solution of the corresponding original TB2 task and drop anything exceeding 1.5×.
- Review (C2, C4): Skill equivalence and construction discipline are enforced by the fixed transform rules plus random check by human reviewers of the variant tasks; any borderline cases are dropped or revised further (by repeating from step 1).
Variants that fail any step above are discarded or revised further by additional rounds of LLM and human reviewers. In the final round, only those tasks that survive all checks enter the evaluation.